What is LoRA in Stable Diffusion and How to Use It
Updated on
In the ever-evolving world of AI-generated art, Stable Diffusion has emerged as a game-changer, empowering artists and creators with an unprecedented level of control over the image generation process. However, what if you could take this control a step further and tailor the model to your specific artistic vision or subject matter? Enter LoRA (Low-Rank Adaptation), a revolutionary technique that allows you to efficiently fine-tune and adapt Stable Diffusion to your unique needs.
In this Stable Diffusion guide, we'll dive deep into the world of LoRA, exploring its inner workings, its applications within Stable Diffusion, and practical examples of how to harness its power. Whether you're a seasoned artist or a curious newcomer to the realm of AI-generated art, this guide will equip you with the knowledge and tools to unlock new realms of creativity and self-expression.
Before diving into the details of using Stable Diffusion LoRA, consider enhancing your generated art with Aiarty Image Enhancer. One common challenge with Stable Diffusion is achieving high-quality, high-resolution images directly from the generation process. Often, the initial outputs can suffer from noise, lack of sharpness, and lower resolution, which can detract from the overall impact of your artwork.
Aiarty Image Enhancer addresses these pain points by leveraging advanced AI technology to upscale, denoise, and sharpen your images. This software brings out the finest details, enhances textures, and ensures your artwork looks polished and professional. Whether you're looking to refine intricate designs or simply add a professional touch to your images, Aiarty Image Enhancer provides the tools you need for stunning results. Transform your Stable Diffusion creations effortlessly and see the difference that professional-grade image enhancement can make.


How LoRA Works (Explanation in Both Terminologies and Simple Words)
In short words, LoRA (Low-Rank Adaptation) is a novel approach to efficiently adapt large pre-trained language models and also Stable Diffusion modes to downstream tasks while minimizing the storage requirements.
Instead of fine-tuning the entire model, for example, the SD 1.5, which requires storing a separate copy of all model weights for each task, LoRA injects trainable low-rank decomposition matrices into each layer of the pre-trained model during fine-tuning.
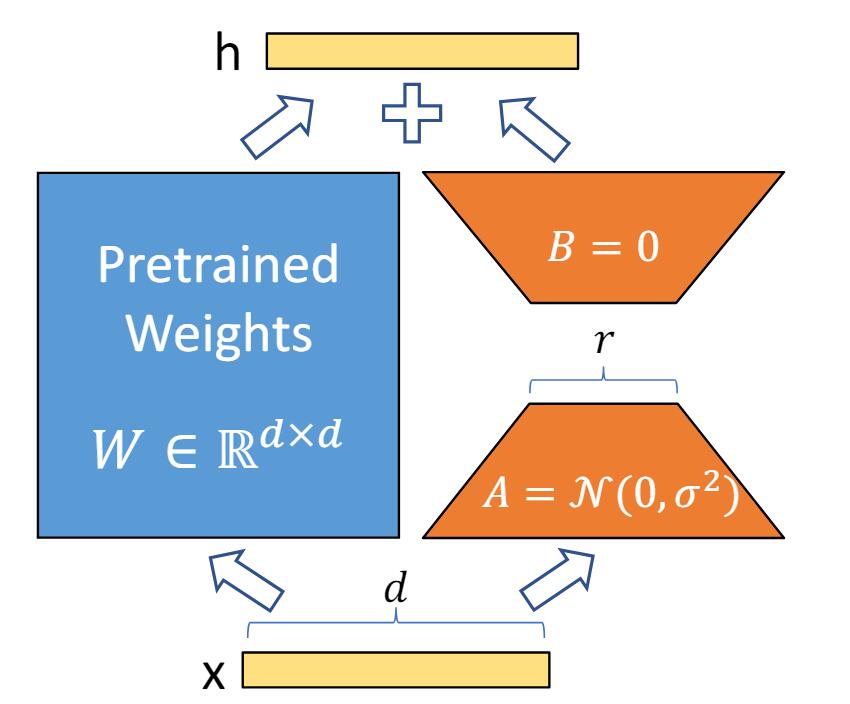
Specifically, for each weight matrix W in the pre-trained model, LoRA computes:
W' = W + BA
Where: W is the original weight matrix from the pre-trained model; B and A are much smaller trainable rank decomposition matrices.
During fine-tuning, only the low-rank matrices B and A are updated, while the pre-trained weights W remain frozen. This allows the model to adapt to the target task via the low-rank updates BA, without modifying the original pre-trained weights.
Considering that these words may still not help you understand this concept very well, if you want to find more details about it, you can go to this original academic paper:
By this approach, what key advantages can it bring?
1. Drastically reduced parameter count: Since only the smaller B and A matrices are trainable, LoRA requires updating far fewer parameters compared to full fine-tuning. For example, for the massive GPT-3 175B model, LoRA only needs to update 0.07% of the parameters.
2. Improved sample efficiency: LoRA can achieve similar or better performance than full fine-tuning while using fewer training examples, improving sample efficiency.
3. Compositionality: Different LoRA updates for various tasks can be easily combined into a single "mixture of experts" model, enabling efficient model composition.
The low-rank decomposition is injected into different types of layers in the pre-trained model, such as multi-head attention layers and feed-forward layers, using different formulations tailored to the layer type.
During inference, the original pre-trained weights W are combined with the trained low-rank updates BA to produce the adapted weight matrices W' for each layer.
Still feel confused?
Now let me try my best to explain LoRA in a simple way that even a 10-year-old kid can understand.
Imagine you have a big book filled with lots of stories and information. This book is like a large language model (LLM) that has learned about many topics from reading a huge amount of text. Now, if you want to learn something new, like how to bake a cake, you don't need to read the entire big book again. Instead, you can just add a small section or chapter about baking cakes to the book. This small addition is like LoRA.
LoRA allows us to adapt or update a large language model to learn new skills or knowledge without changing the entire model. It does this by adding tiny, trainable pieces of information to each layer of the model, instead of updating all the weights and parameters.
These tiny pieces act like little notes or Post-it notes stuck onto the pages of the big book. They provide small updates or changes to the existing information, allowing the model to learn the new task efficiently without forgetting what it already knows.
LoRA and Checkpoint?
In case you have not known about Checkpoint, we will first give an introduction to this concept. In the context of Stable Diffusion, a Checkpoint refers to a saved snapshot of the model's weights and parameters at a specific point during the training process.
Even though both LoRA and Checkpoint work for adapting and fine-tuning large language models like Stable Diffusion, LoRA and checkpoints differ in several key aspects:
1. Purpose: LoRA is a technique for efficiently adapting and fine-tuning large pre-trained models to new tasks or domains while minimizing memory requirements. Checkpoints are saved snapshots of a model's weights and parameters at specific points during training, primarily used for resuming training, evaluating performance, or deploying the model for inference.
2. Parameter Efficiency: LoRA introduces trainable low-rank decomposition matrices into the pre-trained model's layers, updating only a small fraction of the original parameters. Checkpoints store the full set of model parameters, resulting in larger file sizes and higher memory requirements.
3. Customization and Adaptation: LoRA enables efficient customization and domain adaptation of models like Stable Diffusion by fine-tuning with low-rank updates, without storing multiple copies of the full model. Checkpoints do not inherently provide a mechanism for customization or adaptation; they are static snapshots of the model's state.
4. Continual Learning and Compositionality: Techniques like C-LoRA (Continual LoRA) allow for continual customization of Stable Diffusion for multiple, fine-grained concepts in a sequential manner, without suffering from catastrophic forgetting. Checkpoints do not inherently support continual learning or compositionality.
5.Acceleration and Inference: LoRA can be used to distill a smaller, faster "acceleration module" from the pre-trained model, enabling accelerated inference with minimal quality degradation. Checkpoints do not directly provide acceleration capabilities; they are used for resuming training or deploying the model for inference.
What Exactly LoRA Can Do in Stable Diffusion
Based on the LoRA models that we have tried and researched for wiring this blog post, LoRA models in Stable Diffusion can be categorized into the following main types, each serving a different purpose, i.e. what it help you do with your art creations:
1. Style/Aesthetic LoRAs: These LoRAs are trained to apply specific artistic styles, aesthetics, or visual characteristics. By applying such a LoRA model, you can adapt the output of Stable Diffusion to match a desired style, such as anime, pixel art, or a particular artist's style (e.g., Greg Rutkowski). Examples: Arcane style LoRA: Applies the stylized look of the Arcane animated series; Anime Lineart LoRA: Generates anime-style line art images.
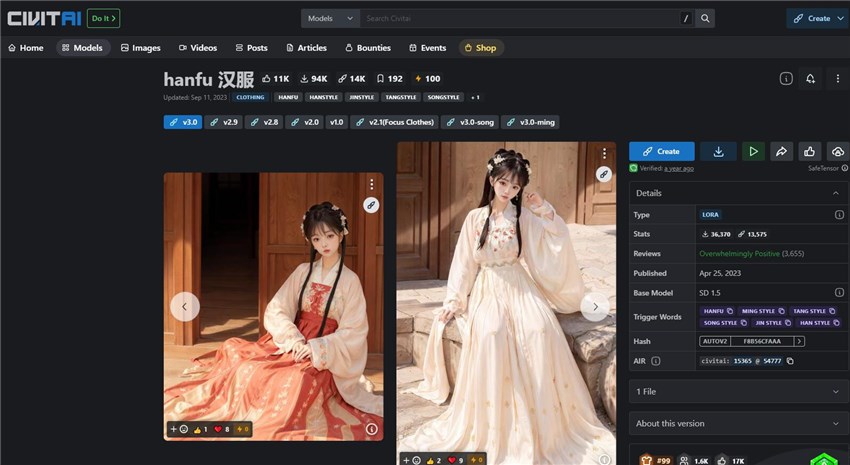
2. Character/Subject LoRAs: These LoRAs are trained on specific characters, people, objects, or subjects to generate accurate depictions of them. This allows you to specialize Stable Diffusion for generating images of those specific concepts more accurately and consistently. Examples: Makima LoRA: Generates images of the character Makima from Chainsaw Man; Hanfu LoRA: Generates images of people wearing traditional Chinese Hanfu clothing.
3. Setting/Environment LoRAs: These LoRAs specialize in generating particular settings, backgrounds, or environments. For example: School Building Scenery LoRA: Generates realistic school building environments.
4. Quality Enhancement LoRAs: These LoRAs aim to improve the overall quality, details, or specific aspects of the generated images. For example: Detail Tweaker LoRA: Enhances sharpness and adds finer details to images.
5. Combination LoRAs: One of the key advantages of LoRA is the ability to combine multiple LoRAs to create custom, tailored models. This enables creating custom models tailored to specific needs by combining different styles, subjects, and enhancements. For example: Combining a character LoRA (e.g., Makima), a clothing LoRA (e.g., her iconic outfit), and a background LoRA to generate scenes with that specific character in that outfit and setting. Or, merging an anime style LoRA, a character LoRA (e.g., Naruto), and a background setting LoRA to create custom anime-style scenes with that character.
How to Install and Use LoRA Models in Stable Diffusion (AUTOMATIC1111 WEB UI)
First thing first, all the operations below showing you how to use Stable Diffusion LoRA work on the application of AUTOMATIC1111.
What is AUTOMATIC1111?
Automatic1111, also known as A1111 or AUTOMATIC1111's Web UI, is a popular open-source user interface for running Stable Diffusion locally on your computer. It provides a graphical interface with various features and tools to generate, edit, and control AI-generated images using Stable Diffusion.
And for sure, Automatic1111 natively supports applying Stable Diffusion LoRA models.
To apply some Stable Diffusion LoRA model in it, you need to first get the model that you prefer. So the question is how or where you can download a Stable Diffusion LoRA model?
There are two popular options or platforms that you can refer to,
Civitai - This is one of the most popular repositories for sharing LoRA models trained by the community. You can browse and download LoRA models for various styles, characters, concepts etc.
HuggingFace - Many LoRA model creators also upload their models to HuggingFace, which is a platform for sharing machine learning models and datasets.
Before you start the downloading from these two platforms, you must have known that a single LoRA model cannot work, and it must work with a main Stable Diffusion model. So When you download a LoRA model, please check what kind of main Stable Diffusion model it was trained based on and make sure that it works with your Stable Diffusion model or Checkpoint model.
After you finish downloading the LoRA model (usually a .safetensors or .pt file), navigate to the stable-diffusion-webui/models/Lora directory in the AUTOMATIC1111 folder, and place the downloaded LoRA model file(s) inside this Lora folder.
Next, it's time to run and open the AUTOMACTIC1111 WEB UI. Go to txt2image or img2img, scroll down a little bit, and find the LoRA tab, which is right next to Checkpoint.
Click it and then it will show you all the LoRA models that you have downloaded and installed into Stable Diffusion.
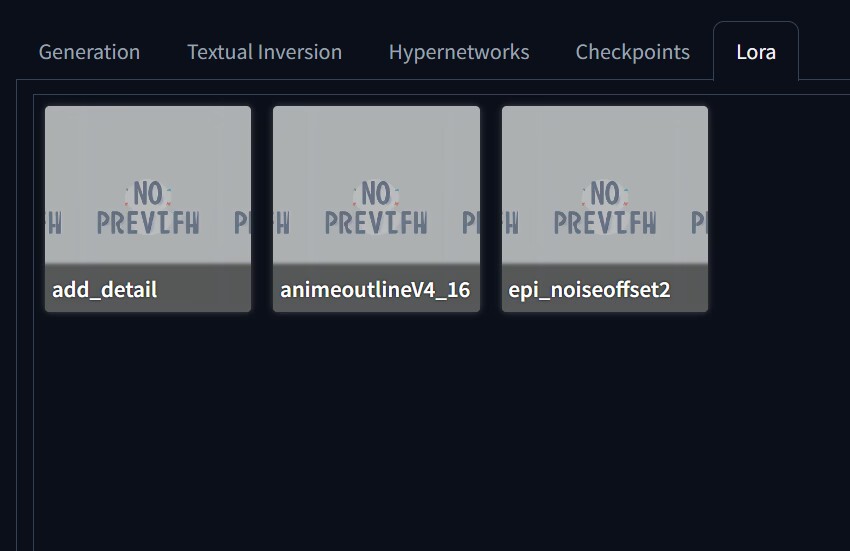
To use one or more of them, go to the prompt box, click one LoRA model, and it will appear in the prompt box. Click another one to add more.
That's it. It is all about how to install and use the LoRA model in Stable Diffusion.
Over to You
When you get here, you have learned almost all basic information and knowledge about the Stable Diffusion LoRA concept. The next step that you need to do is put it into practice. It is certain that you will get more familiar with and understanding of Stable Diffusion Lora after you use it more often in your AUTOMATIC1111 WEB UI.