Best Stable Diffusion Models (2026): Top Picks for Realistic, Anime & More
Updated on
Choosing the right Stable Diffusion model can instantly make or break your results. If you're generating blurry faces, inconsistent styles, or spending hours testing different checkpoints — the problem is usually not your prompt, but the model itself.
In 2026, several Stable Diffusion models clearly stand out: SDXL remains the best overall and most beginner-friendly option, while Realistic Vision / RealVisXL excel at photorealistic images, Anything v5 / AAM XL are ideal for anime styles, and Juggernaut XL delivers cinematic, high-detail results.
This guide is not just a long list — it's a tested and categorized breakdown to help you quickly find the best Stable Diffusion model for your exact use case.
If you’re short on time and just want the highlights, here’s a quick breakdown of the top models to try. Each category below represents a standout choice based on performance, style, and community feedback. The best Stable Diffusion model depends on your goal:
- Best Overall: SDXL
- Best All-Purpose & Creator-Focused Model: Z-Image (excels at portraits, products, stylized art, and graphic-ready outputs)
- Best Realistic: Realistic Vision / RealVisXL V4.0
- Best Anime: Anything v5 / AAM XL AnimeMix
- Best Fantasy & Sci-fi: DreamShaper
- Best Photographic & Cinematic: Juggernaut XL v9
- Best 4K / High-Resolution Model: ThinkDiffusion XL (community-trained high-res specialist)
- Best Newcomer 2025: SD 3.5 Large (the next evolution beyond SDXL)
- Best Versatile Pro Suite: Flux 1.1 Pro / Ultra / Raw
- Best Next-Gen Architecture: Flux 2 (more stable, faster, and sharper across complex scenes)
If you're unsure, start with SDXL, then refine your results using LoRA models.
6 Best Stable Diffusion Models of All Time
If you're not sure which model to choose, this quick comparison will help:
| Model | Best For | Strength | Weakness |
|---|---|---|---|
| SDXL | All-purpose | Versatile, high-quality output across styles | Weak text rendering |
| Z-Image | All-purpose & fast generation | Fast inference, strong prompt alignment, good realism | Smaller ecosystem, less LoRA support |
| Realistic Vision | Photorealism | Excellent human faces and realistic details | Limited style flexibility |
| DreamShaper | Fantasy & illustration | Strong artistic style, great for sci-fi and creative scenes | Less realistic outputs |
| Anything v5 | Anime | Strong anime style with vibrant visuals | Not suitable for realism |
| Juggernaut XL | Cinematic images | High detail, cinematic lighting and composition | Resource intensive |
SDXL — Best Overall Stable Diffusion Model
Best for beginners, general creators, and anyone who wants reliable results without over-optimization
If you only want to install one model, SDXL is still the safest choice in 2026. It performs reliably across almost every use case — from portraits and product shots to landscapes and stylized art — without requiring complex prompts or heavy tuning. This makes it an ideal starting point for beginners, while still being powerful enough for experienced creators.
As the flagship model from Stability AI, SDXL is known for its exceptional versatility and ability to generate highly detailed, lifelike images across a wide range of styles, including realism, anime, and illustration. Trained on 1024×1024 images, it delivers strong overall quality and consistency. However, it still struggles with accurate text rendering.
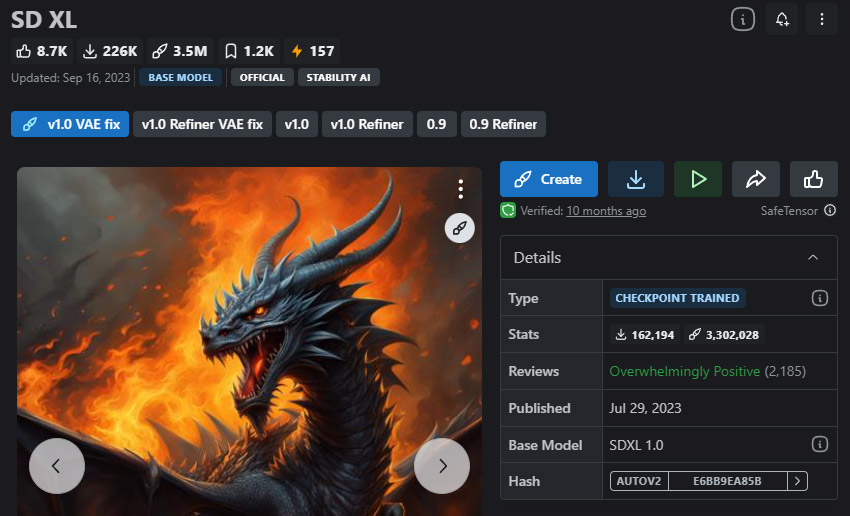
- Delivers consistently high-quality images at 1024×1024 resolution.
- Handles both realism and artistic styles better than most models.
- Strong ecosystem support (LoRA, fine-tunes, tools).
- Text generation is still unreliable.
- Requires SDXL-compatible LoRAs.
- lightly heavier than older SD 1.5 models.
Z-Image — Best All-Purpose Model for Speed and Quality
Best all-purpose & creator-focused model, powered by the new S3-DiT architecture for fast, high-quality image generation.
Z-Image is a next-generation model built on the new S3-DiT (Scalable Single-Stream Diffusion Transformer) backbone. Unlike traditional dual-stream architectures, Z-image processes text and image inputs through a single unified pathway from the start. This simplified and highly efficient design enables the model to run faster while maintaining impressive visual fidelity.
With just 6 billion parameters, Z-image remains lightweight but surprisingly capable, delivering consistent photorealism, strong stylistic control, and better text rendering performance than many models of similar size. It’s particularly attractive to creators producing portraits, product shots, stylized visuals, and commercial-ready content without needing complex prompting.
The model comes in three variants: Z-image Turbo, a fast version optimized for 8-step inference and ideal for consumer GPUs like the RTX 4090; Z-image Base, the non-distilled version suited for fine-tuning and LoRA training; and Z-image Edit, a specialized model designed for instruction-based image editing.

- Efficient S3-DiT architecture with fast, high-quality output.
- Excellent for portraits, products, and stylized commercial visuals.
- Supports multiple variants, including Turbo, Base, and Edit.
- Text rendering improved but still not fully reliable.
- Hand poses and complex multi-object scenes may require refinement.
- Smaller ecosystem of LoRAs compared to SDXL.
Realistic Vision — Best for Photorealistic Images
Best for: portraits, product shots, lifestyle photography, and commercial visuals
If your goal is to generate images that look like real photos, Realistic Vision is one of the most reliable models available. It excels at rendering natural skin tones and facial details, realistic lighting and shadows, and clothing textures and fine details. Compared to SDXL, it produces more lifelike humans with less prompt effort.
But there are also limitations to consider, such as not ideal for fantasy or stylized art, and less flexible across different styles.
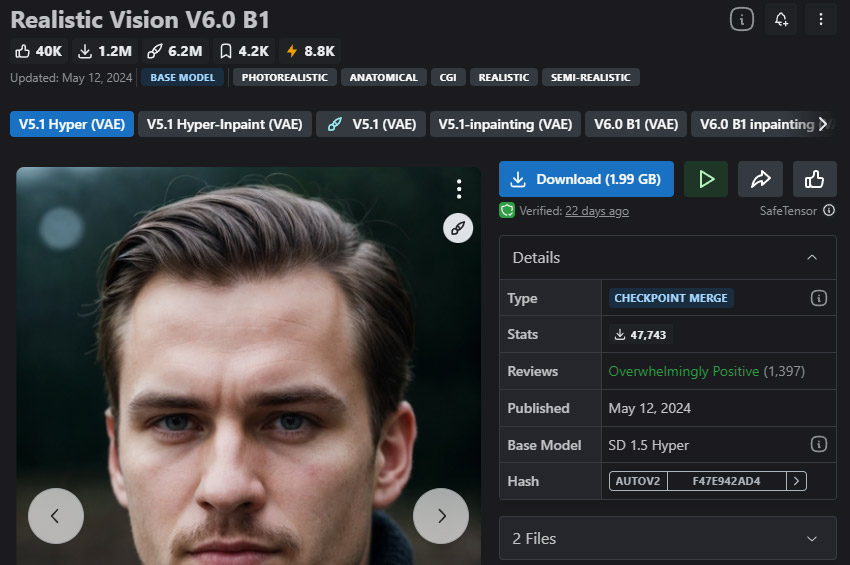
- Extremely suitable for generating realistic humans.
- Generated images are highly detailed and very realistic.
- Supports NSFW.
- Inpainting version available.
- Can't generate any fantasy environments or images.
DreamShaper — Best for Fantasy & Illustration
Best Stable Diffusion model for fantastical and illustration realms and sci-fi scenes.
DreamShaper is the top pick for those seeking exceptional worlds, such as sci-fi and cyberpunk style visuals. With its distinct design, it strives to bring forth mystical environments, mythical creatures, and fantastical landscapes. DreamShaper is meticulously designed to create visuals reminiscent of artwork, drawing inspiration from anime in realistic painting style. Its impressive capability lies in crafting characters set against breathtaking backdrops.
The Stable Diffusion model is an excellent tool for creating images that span a diverse array of themes, ranging from realistic depictions to creative and dreamlike compositions, featuring unique beings, animals, objects, landscapes, and beyond.
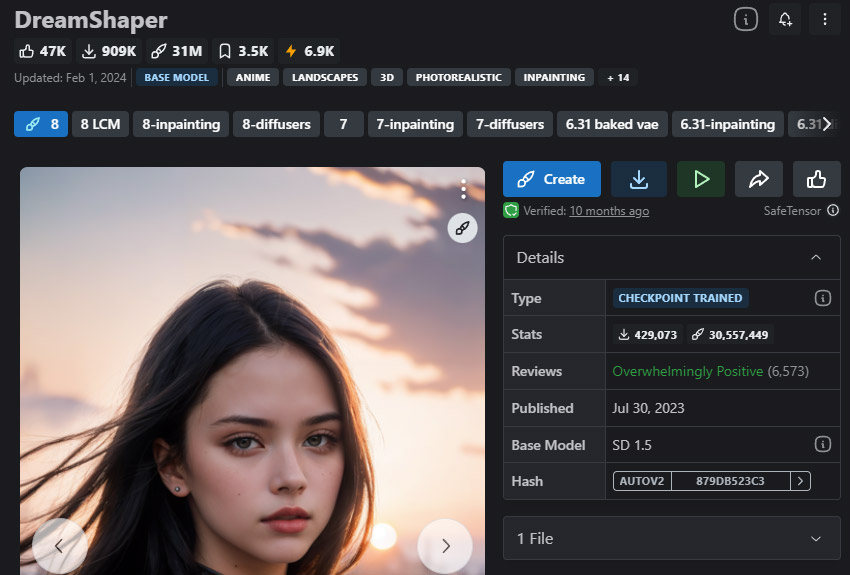
- Excellent in creating sci-fi and cyberpunk themes.
- Ideal for both photorealism and anime styles.
- Inpainting version available.
- Supports NSFW.
- Not ideal for generating realistic images.
Anything v5 — Best for Anime Styles
Best Stable Diffusion model for anime styles and cartoonish appearance.
Anything v5 is a customized Stable Diffusion model designed to create captivating visuals that evoke the essence of your beloved anime and manga. Anticipate vivid colors, expressive characters, and dynamic compositions that breathe life into the world of anime. Especially, this model is designed with the intention of crafting scenes commonly found in Japanese anime.
Anything v5 can create characters and landscapes in the style of anime or illustration. When it comes to generating a portrait, it excels at producing a youthful main character with numerous intricate design elements. Despite its animated appearance, Anything is capable of creating beautiful settings with a gentle color palette.
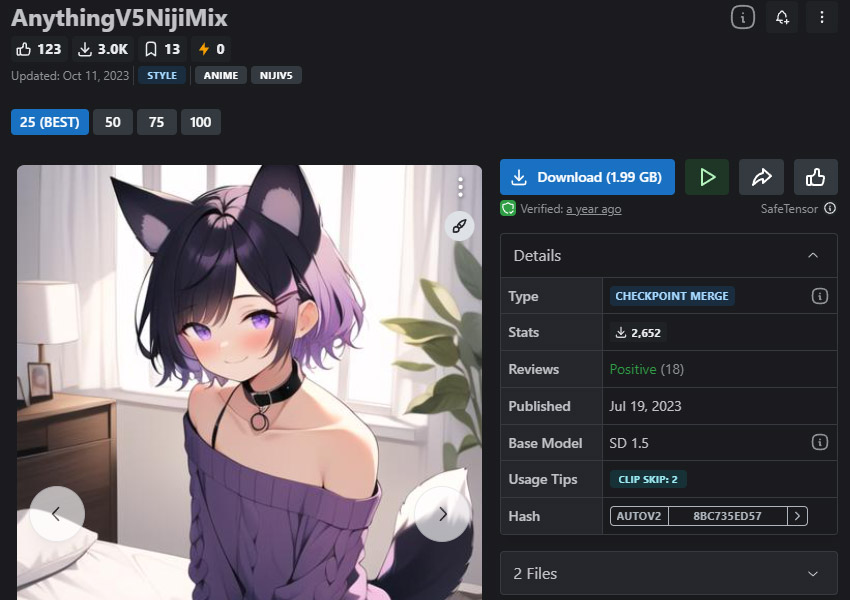
- Covers a lot of anime art styles.
- Generates anime characters and backgrounds with a realistic vibe.
- Create one that’s fully colorful with popping colors.
- Generates intricate shapes and elements.
- Supports NSFW.
- Towards generating female characters.
- Create scenes typical of the Japanese genre.
- Requires some experimentation with VAE.
Juggernaut XL
Best Stable Diffusion model for photography-style images/real photos.
Juggernaut XL is an exceptional successor to the SDXL model for those seeking to push its limits. The refined version offers enhanced detail and fidelity, making it perfect for producing hyperrealistic images that seamlessly blend digital artistry with photography. Its remarkable ability to capture intricate details with utmost clarity makes it an invaluable tool for creating a diverse range of subjects, be it full-bodied human figures, objects, logos, or landscapes. This makes it particularly advantageous for crafting photorealistic portraits or fashion illustrations that demand a distinctive and unparalleled finish.
Juggernaut XL has been upgraded with specialized training in cinematic images, elevating the natural and cinematic quality of the resulting images. For individuals seeking to create images that capture the genuine essence of real photos, the Juggernaut XL provides an immersive experience.
- Perfect for photorealistic still photos and shots with a cinematic look.
- Handles variations in image size with ease.
- Works with SDXL LoRA models.
- Supports NSFW.
- Resource intensive.
- Not always photorealistic.
- Steeper learning curve.
Stable Diffusion Models Still Leading in 2026
Stable Diffusion keeps evolving, and 2026 has already introduced exciting advancements. From hardware-optimized releases to next-generation editing capabilities, here are the biggest updates you should know about.
LoRA Models (Low-Rank Adaptation)
LoRA models have become a core part of the Stable Diffusion ecosystem. Instead of replacing base checkpoints, LoRAs act as lightweight add-ons that inject specific styles, characters, or concepts into models like SD 3.5 Large. This makes them ideal for creators who want flexibility without managing multiple heavy models.
Key Features of LoRA Models:
- Lightweight model extensions, typically only a few hundred MB, compared to multi-GB base checkpoints.
- Designed to add or modify specific elements such as art styles, characters, clothing, or lighting.
- Stackable and adjustable, allowing multiple LoRAs to be combined with different strength values.
- Fully compatible with modern base models like SD 3.5 Large, SDXL, and fine-tuned variants.

SD 3.5 Large
SD 3.5 Large represents a leap forward from the 3.0 series, emphasizing quality and versatility across multiple styles. Alongside it, SD 3.5 Medium provides a balanced option for everyday creators, while SD 3.5 Large Turbo focuses on speed, enabling faster iterations with slightly lighter detail. Together, these variants make the SD 3.5 family suitable for users of all levels, from hobbyists to industry professionals.
Key Features of SD 3.5 Large:
- The flagship release of Stability AI’s 2025 lineup, trained with broader datasets and optimized for even higher fidelity.
- Generates images with greater accuracy, detail, and stylistic range than earlier versions.
- Designed for professional use, with strong support for both creative and commercial projects.

Flux Series (Flux 1.1 → Flux 2)
The Flux family represents one of the most significant evolutions in modern diffusion models, moving from the highly popular Flux 1.1 series into the more advanced and stable Flux 2. Each generation focuses on creative expressiveness, cinematic styling, and prompt flexibility—while Flux 2 introduces major improvements in coherence, detail quality, and speed. Together, the Flux lineup offers a wide range of options for artists, designers, and creators who want consistent control across styles and resolutions.
Flux 1.1 Series:
- Flux 1.1 Pro: A balanced, professional model designed for broad prompt coverage and cinematic rendering.
- Flux Ultra: Optimized for high-resolution output with sharp 4MP generations.
- Flux Raw: Focused on photorealism, delivering lifelike skin textures, lighting, and photographic detail.
- Flux Kontext (2025): Introduces context-aware editing and smarter scene understanding for advanced workflows.
Flux 2 Improvements:
- Stronger coherence: Handles multi-subject scenes, hands, and detailed compositions with higher accuracy.
- Sharper output quality: Enhanced textures, lighting transitions, and overall fidelity compared to Flux 1.1.
- Faster inference: Optimized efficiency for quicker iteration across both creative and commercial projects.
- Better prompt alignment: Reduced drift and more predictable response to descriptive prompts.
- Retains the Flux look: Maintains the cinematic, expressive aesthetic that made Flux 1.1 widely popular.

More Favorites Stable Diffusion Models
Even as new models arrive, proven favorites from 2024 and 2025 remain highly relevant. RealVisXL and AAM XL AnimeMix dominate their niches, while Playground v2.5 and ThinkDiffusion XL provide artistic variety and technical excellence. They’re stable, reliable, and still worth your time in 2026.
- RealVisXL V4.0: remains a top realistic XL model for lifelike human and object rendering.
- AAM XL AnimeMix: continues to lead as the go-to anime-focused model.
- Playground v2.5: praised for its highly artistic and creative outputs.
- ThinkDiffusion XL: a strong pick for generating crisp 4K resolution images.
Improve Your Stable Diffusion Results Further
Even the best models can generate images with noise, blur, or compression artifacts. If you want to enhance your outputs for professional use (e.g., print, product images, or portfolios), you can upscale images to 4K or higher, remove noise and blur, and recover fine details. This is where Aiarty Image Enhancer can significantly improve your final results.

40+ Stable Diffusion Models List
If you want to explore beyond the top picks, here’s a broader list of Stable Diffusion models categorized by style.
Tip: Instead of trying everything, start with 2–3 core models (like SDXL + one specialized model) and expand using LoRAs.
| Image Style | Model Name | Model Type | Base Model |
|---|---|---|---|
| Realistic: Product | SDXL Product Shot | LORA | SDXL 1.0 |
| Realistic: Humans | ChilloutMix | LORA | SD 1.5 |
| Realistic: Landscapes/Animals | NextPhoto | Checkpoint | SD 1.5 |
| Realistic: Games/Architectures | RealVisXL | Checkpoint | SDXL 1.0 |
| Realistic: Nighttime | NightVisionXL | Checkpoint | SDXL 1.0 |
| Realistic: Food | Food Photography | LORA | SD 1.5 |
| Realistic: Fashion | Modern Vision | Checkpoint | SD 1.5 |
| Portraits | Modelshoot | Checkpoint | SD 1.5 |
| Manga | MANGA (General) | LORA | SD 1.5 |
| Anime Art | VaporWaveV1 | LORA | SD 1.5 |
| Cartoon | ToonYou | Checkpoint | SD 1.5 |
| Comic Book | Comic Diffusion | Checkpoint | SD 1.5 |
| Pixel Art | Pixel Art XL | LORA | SDXL 1.0 |
| Illustration | Vector Art | Checkpoint | SD 2.1 |
| Futuristic | Futuristic XL | LORA | SDXL 1.0 |
| Cyberpunk | CyberpunkAI | LORA | SD 1.5 |
| Sci-Fi | Sci-fi XL Style | LORA | SD 1.5 |
| Surrealism | ColorfulSurrealismAI | Checkpoint | SD 1.5 |
| Retro | RetroMix | Checkpoint | SD 1.5 |
| Vintage | PhotoVintageV1.5 | Checkpoint | SD 1.5 |
| Oil Painting | Oil Painting | LORA | SD 1.5 |
| Watercolor | Watercolor | LORA | SD 1.5 |
| Pencil Drawing | Pencil Drawing | LORA | SDXL 1.0 |
| Graffiti | Flonix’s Vector Style | Checkpoint | SDXL 1.5 |
| Caricature | Krueger Caricature Style XL | LORA | SDXL 1.0 |
| Cinematic | Juggernaut Cinematic XL | LORA | SDXL 1.0 |
| Bokeh | Copax Bokeh | LORA | SD 1.5 |
| 3D Style | 3D Rendering Style | LORA | SD 1.5 |
| Interior Design | InteriorDesignSuperMix | Checkpoint | SD 1.5 |
| Art Deco | Art Deco Fusion | LORA | SD 1.5 |
| Flat Design | Lineart Flat Colors | LORA | SD 1.5 |
| Low Poly | Low Poly | LORA | SDXL 1.0 |
| Line Art | Niji Lineart | LORA | SD 1.5 |
| Vector Art | vector-art | Checkpoint | SD 2.1 |
| Gothic | GothicpunkAI | LORA | SD 1.5 |
| Architecture | ArchitectureRealMix | Checkpoint | SD 1.5 |
| Fauvism | Paragon | Checkpoint | SD 1.5 |
| Renaissance | Renaissance XL | LORA | SDXL 1.0 |
| Paper Cut | Papercut SDXL | LORA | SDXL 1.0 |
| Silhouette | Silhouette | LORA | SD 1.5 |
| Fluorescent | Fluorescent Green | LORA | SD 1.5 |
| Iridescent | Made Of Iridescent Foil | LORA | SD 2.1 |
Where to Find the Best Models for Stable Diffusion?
When exploring Stable Diffusion, knowing where to find quality models can save time and enhance your creations. Here are the top sources:
- Civitai: The leading community hub for Stable Diffusion models. You can find checkpoints, LoRAs, textual inversion models, and more. Simply visit civitai.com, go to the Models section, and filter by model name, type, base model, or status. Tip: Stick to 3–5 core models to avoid overwhelm, and experiment with LoRAs for fine-tuning.
- Hugging Face: Offers official checkpoints and experimental releases, making it a great choice for exploring new or cutting-edge models.
- Stability AI: Provides the official SDXL and SD 3.0/3.5 releases, ensuring reliable performance and compatibility.
- Ikomia / AI Blogs: Ideal for side-by-side comparisons, benchmarks, and insights into how different models perform in practice.
 FAQs about Stable Diffusion Model
FAQs about Stable Diffusion Model
As of now, the most powerful Stable Diffusion models are SD 3.5 Large, Flux 2, and Z-image. SD 3.5 Large offers the highest overall fidelity, Flux 2 delivers the best cinematic and coherent outputs, and Z-image provides fast, high-quality generation with strong realism. The “best” choice depends on whether you prioritize accuracy, style control, or speed.
Realistic Vision is the best realistic model for Stable Diffusion. It is especially good at generating realistic humans with real faces and eyes.
Anything V5 is the best Stable Diffusion anime model to create characters and landscapes in anime style or cartoonish appearance. However, it focuses on creating scenes typical of the Japanese genre. Check more Stable Diffusion anime models >>
Stable Diffusion utilizes a type of AI model known as a "diffusion model", specifically a Latent Diffusion Model (LDM) developed by the CompVis group at LMU Munich. This model is designed for high-quality image synthesis and is part of the family of generative models.
There are two main places to get models for Stable Diffusion, including Civitai and Hugging Face.
You May Also Like
Rico Rodriguez is an experienced content writer with a deep-rooted interest in AI. He has been at the forefront of exploring generative AI tools like Stable Diffusion. His articles offer valuable insights into the world of AI, providing readers with practical tips and informative explanations.